No es la primera vez que escuchamos que una inteligencia artificial haya aprendido a jugar a un videojuego. Siguiendo el hilo de la IA que va a participar en ‘The International’ de Dota 2 o la que aprendió a jugar clásicos de Atari, nos encontramos con Google Deepmind, que aprendió a jugar al shooter Quake III.
PUBLICIDAD
A la gran compañía le llamó muchísimo la atención cómo en nuestra sociedad los individuos trabajan en grupo para conseguir un objetivo en común. Básicamente, cooperación y comunicación entre entidades independientes para afrontar un problema. Esto lo equipararon con los efectos de los videojuegos, sobre todo los multijugador. Dicho modo de juego invita a crear estrategias y coordinarse con otros para conseguir la victoria.
Así que a Google le pareció buena idea elegir al clásico de 1999 Quake III como su campo de pruebas. Bueno, no exactamente… tomaron el juego y crearon una versión simplificada para que pudiera trabajar su inteligencia artificial. Le ordenaron que buscara la manera de ganar en un típico juego de Captura la Bandera (CTF). De este modo, creó varios ‘agentes’ individuales que tenían que competir entre sí en partidas de 5 minutos. Así es como se ve:
Desarrollo de tácticas y aumento de ‘Elo’
Cada agente es una versión idéntica de la inteligencia artificial que compite con otros. Son 30 en total, y cada uno va aprendiendo una propio estilo de juego.
Cabe aclarar que los agentes no poseen una información general del juego. Se tienen que defender solo con la información que obtienen desde la vista en primera persona de su personaje.
Solo se da la instrucción de ganar el juego, pero no las formas para hacerlo. Los agentes debían aprender a cómo ver, actuar, cooperar, desplazarse, etc. Lo único que se hace es recompensar cuando se cumple con la tarea (anotar un punto con la bandera enemiga).
Para hacerlo todo más difícil, el mapa variaba aleatoriamente en cada uno de los juegos. De esta forma se asegura que la inteligencia artificial emplee estrategias generales y no uno solo para un mapa específico.
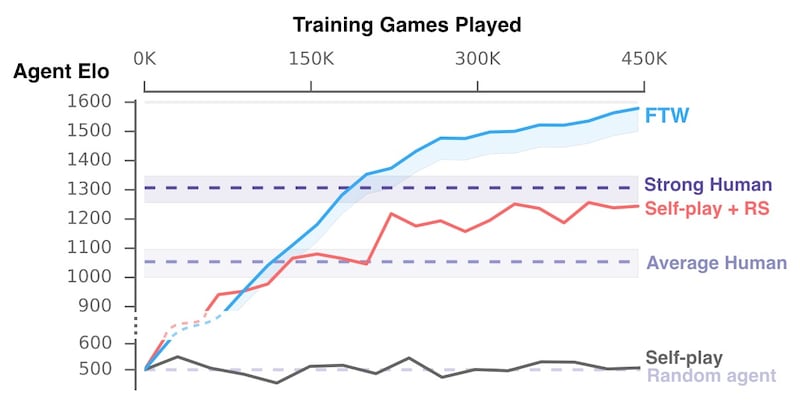
Los agentes jugaron entre sí más de medio millón de partidas de cinco minutos. Al parecer los resultados fueron cada vez mejores, porque adquirieron algunas habilidades consideradas «de humanos». Por ejemplo, desarrollaron capacidades de seguimiento de compañeros de equipo, campeo de base enemiga, o defensa de la base propia.
En cierto punto lograron competir en un mini-torneo en equipos mezclados de IA-IA, humano-IA y humano-humano. Increíblemente los equipos compuestos por la máquina resultaban tener más porcentaje de éxito frente a las personas.
Vemos en la siguiente tabla cómo los agentes mejoraron exponencialmente en el sistema de puntuación Elo. Comenzaron mediocremente con unos 500 puntos, y lograron superar primero a seres humanos promedio e inclusive hasta a los más experimentados por encima de los 1300.
Ciertamente el objetivo final de Google no es enseñarle a Deepmind a jugar videojuegos. Según ellos, este método les puede ayudar a cumplir con problemas mundiales más complejos al estudiar la cooperación y la estrategia que hay en un multijugador.